Conçu pour offrir un débit élevé et une faible latence, Amazon CloudSearch prend en charge une large gamme de fonctions, parmi lesquelles des options de traitement de texte propres à chaque langue et disponibles pour 34 langues, la recherche en texte libre, la recherche à facettes, la recherche géolocalisée, la classification par pertinence personnalisable, la mise en surbrillance des occurrences, le remplissage automatique, la mise à l'échelle configurable par l'utilisateur et des options de disponibilité.
Pour utiliser Amazon CloudSearch, il vous suffit de :
- créer un domaine de recherche,
- configurer les options d'indexation de vos données,
- charger les données à indexer,
- soumettre des requêtes de recherche (Search) depuis votre site Web ou votre application.
Dans la section ci-dessous, vous trouverez des informations au sujet du fonctionnement de CloudSearch.
Essayez Amazon CloudSearch gratuitement
Démarrer un essai gratuit d'Amazon CloudSearchEn savoir plus
Bénéficiez de 750 heures gratuites d'instances de recherche entièrement fonctionnelles pendant 30 jours. Pour commencer :
Connectez-vous à votre compte AWS et lancez la console CloudSearch
Créez et configurez un domaine de recherche en quelques clics
Vous pouvez créer un domaine de recherche Amazon CloudSearch pour chaque lot de données collectées que vous souhaitez rendre consultable. Le domaine de recherche inclut vos données, ainsi que les ressources matérielles et logicielles requises pour exécuter un moteur de recherche. Chaque domaine de recherche possède au moins une instance de recherche. Une instance de recherche est une instance de serveur comprenant un nombre fini de ressources RAM et CPU pour l'indexation des données et le traitement des requêtes. Le nombre d'instances de recherche d'un domaine dépend des documents figurant dans votre lot de données collectées, ainsi que du volume et de la complexité de vos requêtes de recherche.
En tant que service de recherche géré, Amazon CloudSearch détermine la taille et le nombre d'instances de recherche (Search) nécessaires pour garantir des performances de recherche avec une latence minimale et un débit optimal. Lorsque vous créez un domaine de recherche, Amazon CloudSearch utilise par défaut une instance de recherche de type Small (search.m1.small). Vous pouvez sélectionner un type d'instance de recherche plus large afin d'augmenter la capacité de mise à jour de votre domaine et de réduire les délais de chargement et d'indexation lorsque les volumes de données collectées sont importants. (Si les capacités du type d'instance le plus large ne suffisent pas à répondre à vos besoins, vous pouvez augmenter le nombre d'instances sur lesquelles votre index est partitionné.)
A mesure que le volume de données au sein de votre index de recherche augmente, Amazon CloudSearch met automatiquement à l'échelle votre domaine de recherche. Dès que votre index dépasse la capacité du type d'instance utilisé, le domaine est mis à l'échelle vers le type d'instance directement supérieur. Si votre index de recherche dépasse la capacité du type d'instance le plus large, Amazon CloudSearch partitionne l'index sur différentes instances. Inversement, en cas de diminution de la taille de votre index, CloudSearch met à l'échelle votre domaine vers un type d'instance de recherche de plus faible envergure ou réduit le nombre de partitions.
Amazon CloudSearch effectue également une mise à l'échelle automatique pour prendre en charge toute hausse du trafic de recherche. Dès qu'une instance de recherche est sur le point d'atteindre sa charge maximale d'interrogation, CloudSearch en déploie un réplica. A l'inverse, si le trafic de recherche diminue, Amazon CloudSearch supprime les réplicas devenus inutiles afin de limiter les coûts.
Par exemple, un index de recherche divisé en trois partitions utilise trois instances de recherche (soit une par partition). Lorsque le trafic de recherche augmente au-delà des capacités de traitement des différentes instances de recherche, les partitions sont répliquées afin de fournir des capacités d'interrogation supplémentaires. Une fois les instances répliquées, le domaine dispose de six instances de recherche au total, deux pour chaque partition. Si le trafic continue de croître, Amazon CloudSearch ajoute autant de réplicas que nécessaire.
Si vous vous attendez à un trafic de requêtes important ou à un pic de trafic considérable, vous pouvez ajouter explicitement d'autres réplicas des instances de recherche dans votre domaine.

Vous avez la possibilité de consulter les ressources utilisées par vos domaines Amazon CloudSearch en vous rendant sur la page Activité du compte du site Web d'AWS, en utilisant AWS Management Console ou en soumettant une requête d'API CloudSearch via l'interface de ligne de commande (CLI, Command Line Interface) ou les kits de développement logiciel (SDK) d'AWS.
Le volume de données pris en charge par chaque type d'instance de recherche dépend essentiellement de la taille des documents à indexer et des options d'indexation définies pour votre domaine.
Pour comprendre les capacités de chaque type d'instance de recherche, prenons un exemple de document et de configuration correspondant à l'ensemble de données de l'application IMDb. L'exemple ci-dessous concerne un document de données cinématographiques IMDb d'1 Ko environ :
{
"fields" : {
"directors" : [
"Francis Lawrence"
],
"release_date" : "2013-11-11T00:00:00Z",
"genres" : [
"Action",
"Adventure",
"Sci-Fi",
"Thriller"
],
"image_url" : "http://ia.media-imdb.com/images/M/MV5xMzNeMzAx._V1_SX400_.jpg",
"plot" : "Katniss Everdeen and Peeta Mellark become targets of the Capitol after their victory in the 74th Hunger Games sparks a rebellion in the Districts of Panem.","title" : "The Hunger Games: Catching Fire",
"rank" : 4,
"running_time_secs" : 8760,
"actors" : [
"Jennifer Lawrence",
"Josh Hutcherson",
"Liam Hemsworth"
],
"year": 2013
},
"id" : "tt1951264",
"type": "add"
}
Pour indexer des documents de données cinématographiques comme celui-ci et pouvoir y faire des recherches, nous configurerons notre domaine de recherche de manière à associer un champ d'index à chaque champ du document. Nous pouvons définir plusieurs options d'indexation pour chaque champ : type de champ et s'il s'agit d'un champ interrogeable, autorisant les recherches à facettes, renvoyant des résultats, autorisant le tri ou la mise en surbrillance, par exemple. Les options d'indexation ont un impact direct sur la quantité de documents traités par une instance de recherche. Le tableau ci-après présente un exemple de configuration pour les champs d'index de nos documents de données cinématographiques IMDb.
| Nom |
Type |
Recherche |
Facette |
Retour |
Tri | Mise en surbrillance |
|---|---|---|---|---|---|---|
| actors |
text-array |
✔ | – | ✗ | – | ✗ |
| directors |
text-array |
✔ | – | ✗ | – | ✗ |
| genres |
literal-array |
✔ | ✔ | ✗ |
– | – |
| image_url |
texte |
✗ | – | ✗ | ✗ | ✗ |
| plot |
texte |
✔ | – | ✗ | ✗ | ✔ |
| rank | int | ✔ | ✗ | ✗ | ✔ | – |
| rating |
double |
✔ | ✔ | ✗ | ✔ | – |
| release_date |
date |
✔ | ✔ | ✗ | ✔ | – |
| running_time_secs |
int |
✔ | ✔ | ✗ | ✔ | – |
| title |
texte |
✔ | – | ✔ | ✔ | ✔ |
| year |
int |
✔ | ✔ | ✔ | ✔ | – |
En fonction de la taille du document (1 Ko) et de cette configuration d'index, les différents types d'instance de recherche offrent les capacités de traitement indiquées dans le tableau ci-après.
| Type d'instance de recherche | Capacité en données |
|---|---|
| Instance de recherche Small (search.m1.small) |
2 millions de documents |
| Instance de recherche Large (search.m1.large) | 8 millions de documents |
| Instance de recherche Extra Large (search.m2.xlarge) |
16 millions de documents |
| Instance de recherche Double Extra Large (search.m2.2xlarge) | 32 millions de documents |
Bien évidemment, il ne s'agit que d'un exemple. Avec d'autres documents et configurations, le nombre de documents pris en charge par une instance peut s'avérer totalement différent. Si la capacité d'une seule instance de recherche de type Double Extra Large ne suffit pas, Amazon CloudSearch partitionne automatiquement l'index de recherche sur plusieurs instances Double Extra Large supplémentaires. Un index peut être partitionné sur 10 instances de recherche Double Extra Large maximum afin de prendre en charge des dizaines voire des centaines de millions de documents. Si vous avez besoin d'un dimensionnement plus important, contactez-nous.
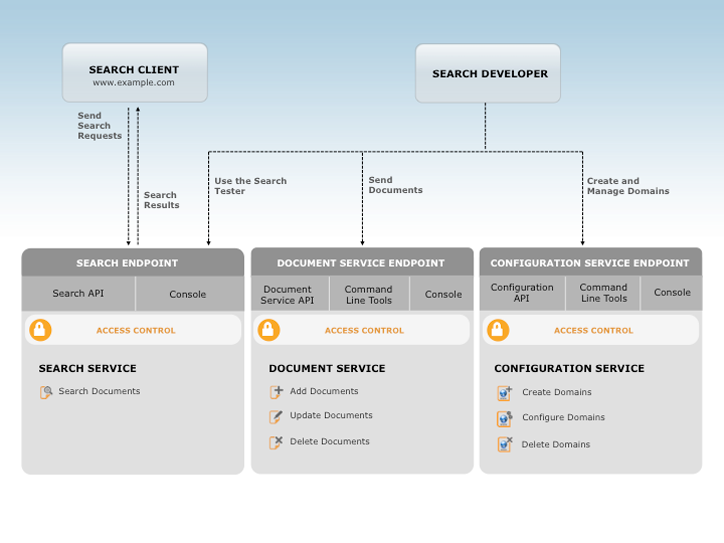
Vous interagissez avec Amazon CloudSearch à travers trois services :
- Service de configuration – Création et configuration de domaines de recherche
- Service de document – Chargement de lots de documents
- Service de recherche – Lancement de requêtes de recherche et de suggestion
Vous utilisez les politiques AWS Identity and Access Management (IAM) afin de gérer les accès au service de configuration d'Amazon CloudSearch, ainsi qu'aux services de document et de recherche de chaque domaine.
Le service de configuration vous permet de créer et de configurer des domaines de recherche. Pour configurer un domaine de recherche, attribuez-lui un nom unique et définissez les options d'indexation, les schémas d'analyse de texte, les options de disponibilité, les options de dimensionnement, les outils de suggestion et les expressions :
- Les options d'indexation déterminent les champs à inclure dans l'index. Vous pouvez utiliser AWS Management Console ou les outils de ligne de commande d'Amazon CloudSearch pour lancer une analyse de vos données et la configuration automatique des options d'indexation par défaut.
- Les schémas d'analyse de texte définissent les options de traitement de texte propres à une langue pour les champs de texte et de matrice de texte. Les schémas d'analyse contrôlent les mots vides qui doivent être ignorés au cours de l'indexation, définissent des synonymes courants pour les termes et précisent comment les termes sont mis en correspondance avec les racines communes.
- Les options de disponibilité vous permettent de déployer un domaine sur deux zones de disponibilité distinctes afin de garantir une haute disponibilité même en cas de perturbations au niveau du service.
- Les options de dimensionnement vous permettent de réaliser une mise à l'échelle anticipée de votre domaine en spécifiant le type d'instance souhaité, ainsi que le nombre de réplicas et de partitions. Cela s'avère notamment utile en cas de volume important de documents à charger ou de prévision de pic dans le trafic de requêtes.
- Les outils de suggestion vous permettent d'extraire des correspondances possibles pour une requête de recherche incomplète, afin que vous puissiez afficher les résultats à mesure que l'utilisateur saisit sa recherche.
- Les expressions sont des expressions numériques évaluées au moment de la requête. Vous pouvez utiliser des expressions pour contrôler le mode de classement des résultats de recherche. Par défaut, les documents sont classés selon leur degré de pertinence, lequel est calculé en fonction de la fréquence des termes recherchés au sein d'un document. Vous pouvez utiliser des expressions pour inclure d'autres facteurs dans le classement. Par exemple, si vos documents comportent un champ numérique intitulé « popularité », vous pouvez définir une expression combinant la popularité avec la note par défaut de pertinence du texte, afin que les documents les plus demandés apparaissent en premier dans vos résultats de recherche.
Le service de document permet de modifier les données consultables d'un domaine. Chaque domaine dispose d'un point de terminaison HTTP unique pour son service de document.
Pour envoyer des données à votre domaine, vous devez les convertir au format JSON ou XML. Chaque élément que vous souhaitez faire figurer dans les résultats de recherche est représenté sous la forme d'un document. Chaque document possède un identifiant unique ainsi qu'un ou plusieurs champs contenant les données sur lesquelles peuvent porter les recherches. Les champs d'un document peuvent contenir n'importe quelles données de chaîne UTF-8. Les options d'indexation de votre domaine définissent la façon dont vous souhaitez indexer et utiliser les données.
Le service de recherche traite les requêtes de recherche et de suggestion associées à un domaine. Chaque domaine dispose d'un point de terminaison HTTP unique. Lorsque vous lancez une requête de recherche ou de suggestion, le service de recherche renvoie la liste des documents répondant aux critères de recherche. Les résultats peuvent être renvoyés au format JSON ou XML.
Amazon CloudSearch fournit un langage de requête enrichi qui vous permet de faire porter la recherche sur certains champs en particulier, d'effectuer des recherches booléennes complexes, d'extraire les informations relatives aux facettes, ou encore de définir les données qui doivent être incluses dans les résultats. Vous pouvez également définir des options permettant de contrôler la façon dont les termes sont traités, et utiliser d'autres analyseurs de requêtes tels que Lucene ou DixMax.
Vous pouvez faire appel au testeur de recherches de la console Amazon CloudSearch pour réaliser des tests à partir d'exemples de requêtes.
Votre utilisation de ce service est soumise au Contrat client Amazon Web Services.