Crea un modello di machine learning
con Amazon SageMaker Autopilot
Amazon SageMaker è un servizio completamente gestito che consente a data scientist e sviluppatori di creare, addestrare e distribuire in modo rapido modelli di machine learning.
In questo tutorial potrai creare automaticamente modelli di machine learning senza la necessità di scrivere alcuna riga di codice. Avrai a disposizione Amazon SageMaker Autopilot, una funzionalità AutoML che crea automaticamente i migliori modelli di machine learning per la classificazione e la regressione, consentendo al contempo di mantenere pieno controllo e visibilità.
Questo tutorial offre le nozioni per:
- Creare un account AWS
- Configurare Amazon SageMaker Studio per accedere ad Amazon SageMaker Autopilot
- Scaricare un set di dati pubblico con Amazon SageMaker Studio
- Creare un esperimento di formazione con Amazon SageMaker Autopilot
- Esplorare le diverse fasi dell'esperimento di formazione
- Identificare e distribuire il modello con le migliori prestazioni dell'esperimento di formazione
- Ottenere previsioni con il tuo modello distribuito
In questo tutorial, assumerai il ruolo di uno sviluppatore di machine learning che lavora in una banca. Ti è stato chiesto di sviluppare un modello di machine learning per prevedere se un cliente aprirà un conto deposito (CD). Il modello verrà addestrato sul set di dati di marketing che contiene informazioni sui dati demografici dei clienti, risposte a eventi di marketing e fattori esterni.
| Informazioni sul tutorial | |
|---|---|
| Durata | 10 minuti |
| Costo | Inferiore a 10 USD |
| Caso d'uso | Machine Learning |
| Prodotti | Amazon SageMaker |
| Destinatario | Sviluppatore |
| Livello | Principiante |
| Ultimo aggiornamento | 12 maggio 2020 |
Fase 1. Crea un account AWS
Il costo di questo workshop è inferiore a 10 USD. Per ulteriori informazioni, visita la pagina dei prezzi di Amazon SageMaker Studio.
Hai già un account? Accedi
Fase 2. Amazon SageMaker Studio
Completa le seguenti fasi per iniziare a usare Amazon SageMaker Studio e accedere ad Amazon SageMaker Autopilot.
Nota: per ulteriori informazioni, consulta la sezione Inizia a usare Amazon SageMaker Studio nella documentazione di Amazon SageMaker.
a. Accedi alla console di Amazon SageMaker.
Nota: nell'angolo in alto a destra, assicurati di selezionare una regione AWS in cui è disponibile Amazon SageMaker Studio. Per un elenco delle regioni, consulta la pagina Onboarding in Amazon SageMaker Studio.


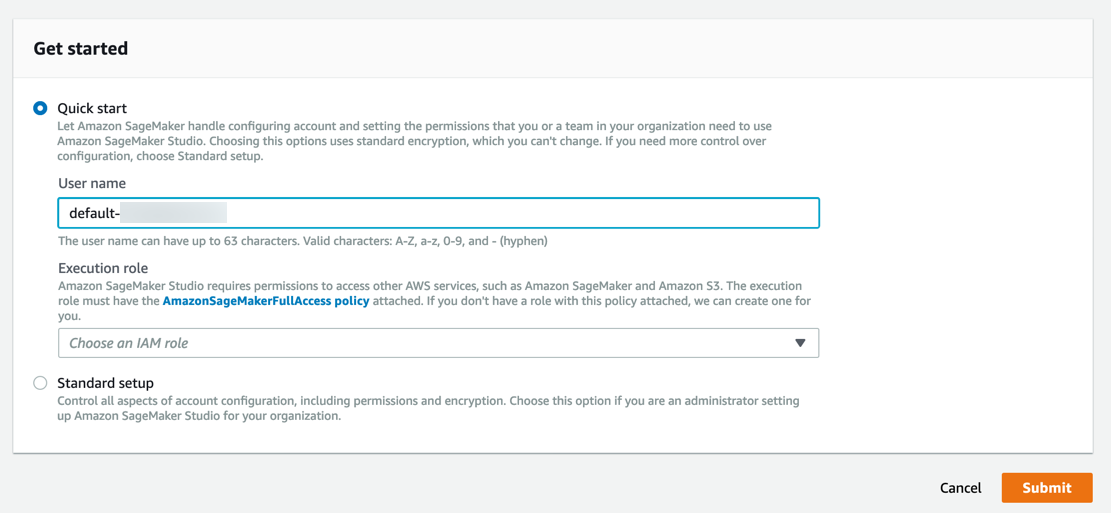
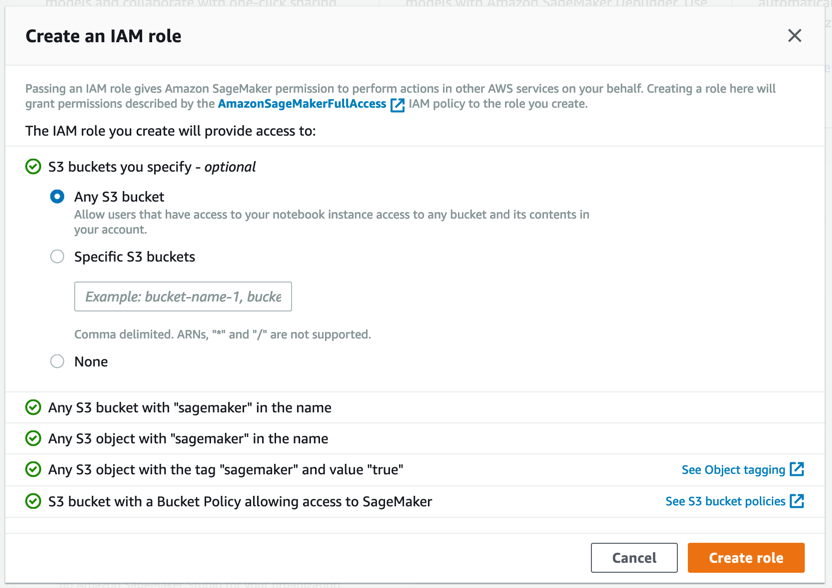
Amazon SageMaker crea un ruolo con le autorizzazioni necessarie e lo assegna alla tua istanza.
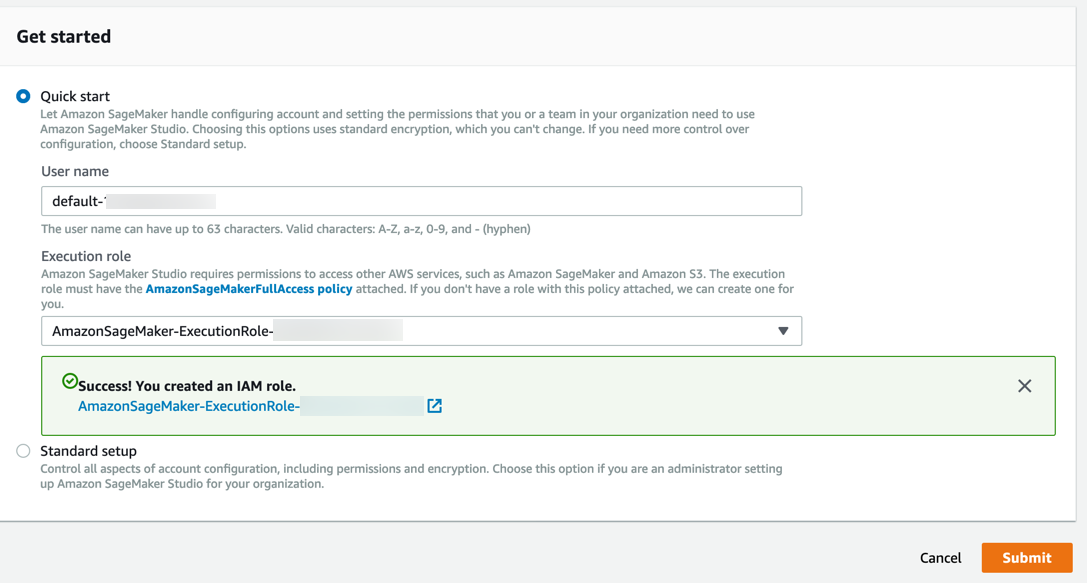
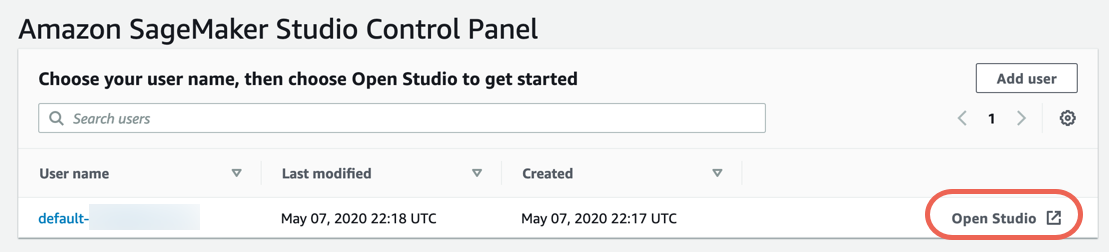
Fase 3. Scarica il set di dati
Completa i seguenti passaggi per scaricare e saperne di più sul set di dati.
Nota: per ulteriori informazioni, consulta la pagina Presentazione di Amazon SageMaker Studio nella documentazione di Amazon SageMaker.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. Copia e incolla il codice seguente in una nuova cella di codice e seleziona Esegui.
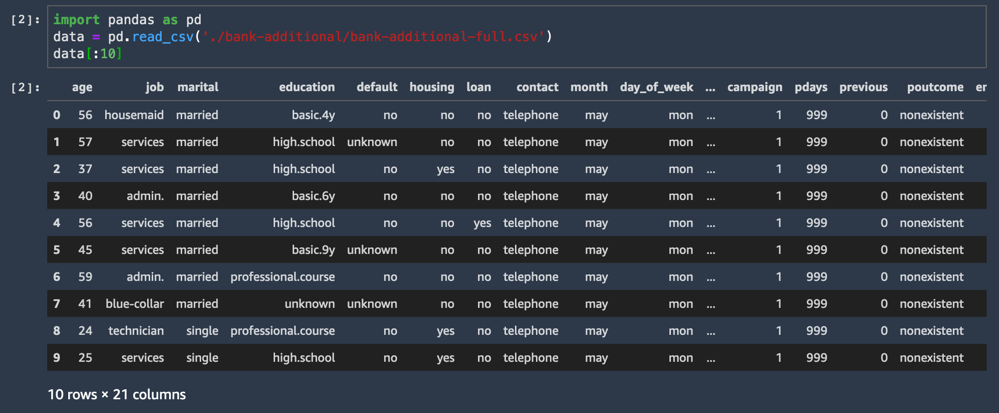
Il set di dati CSV carica e mostra le prime dieci righe.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]Una delle colonne del set di dati è denominata y e rappresenta l'etichetta per ciascun campione: il cliente ha accettato o meno l'offerta?
A partire da questo passaggio, i data scientist inizierebbero ad analizzare i dati, creando nuove funzionalità e così via. Con Amazon SageMaker Autopilot, non è necessario eseguire nessuno di questi passaggi aggiuntivi. Sarà semplicemente necessario caricare i dati tabulari in un file con valori separati da virgola (ad esempio, da un foglio di calcolo o da un database), scegliere la colonna di destinazione su cui eseguire la previsione e Autopilot crea un modello predittivo per te.
d. Copia e incolla il codice seguente in una nuova cella di codice e seleziona Esegui.
Questo passaggio carica il set di dati CSV in un bucket Amazon S3. Non è necessario creare un bucket Amazon S3: Amazon SageMaker crea automaticamente un bucket predefinito nel tuo account durante il caricamento dei dati.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
Hai completato l'operazione con successo. L'output del codice visualizza l'URI del bucket S3 come nell'esempio seguente:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvTieni traccia dell'URI di S3 e appuntalo sul tuo notebook. Ne avrai bisogno nel prossimo passaggio.

Fase 4. Crea un esperimento SageMaker Autopilot
Ora che hai scaricato e organizzato il tuo set di dati in Amazon S3, puoi creare un esperimento Amazon SageMaker Autopilot. Un esperimento è una raccolta di attività di elaborazione e formazione relativi allo stesso progetto di machine learning.
Completa le seguenti fasi per creare un nuovo esperimento.
Nota: per ulteriori informazioni, consulta la sezione Creare un esperimento Autopilot Amazon SageMaker in SageMaker Studio nella documentazione di Amazon SageMaker.
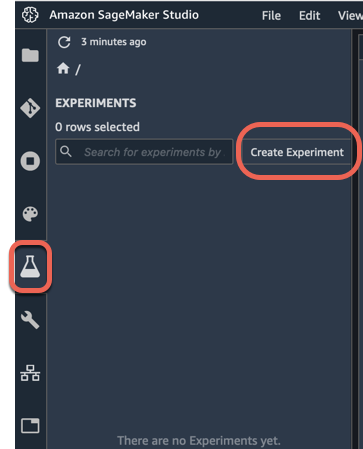
a. Nel riquadro di navigazione sinistro di Amazon SageMaker Studio, scegli Esperimenti(icona simboleggiata da un'ampolla), quindi seleziona Crea esperimento.
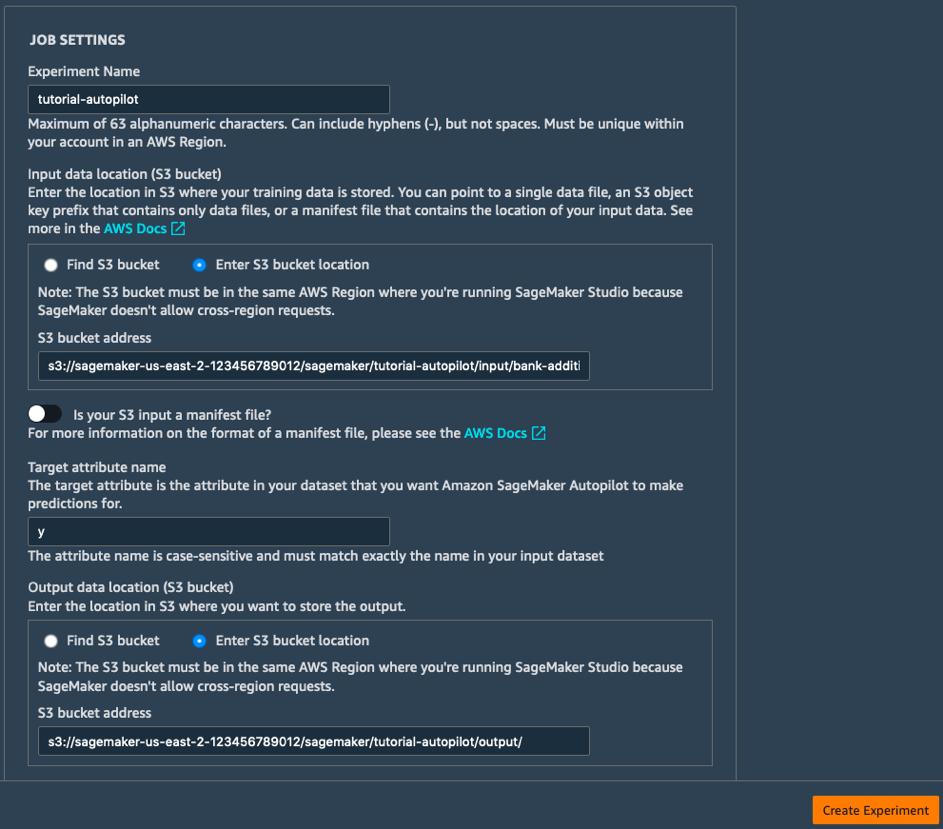
b. Compila i campi Impostazioni attività come segue:
- Nome dell'esperimento: tutorial-autopilot
- Posizione S3 del set di dati di input: si tratta dell'URI di S3 stampato in precedenza
(e.g. s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Nome attributo di destinazione: y
- Posizione S3 del set di dati di output: s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(assicurati di sostituire [ACCOUNT-NUMBER] con il tuo numero di account)
c. Mantieni inalterate tutte le altre impostazioni e seleziona Crea esperimento.
Operazione riuscita. L'esperimento di Amazon SageMaker Autopilot si attiva. Il processo genererà un modello e statistiche visualizzabili in tempo reale durante l'esecuzione dell'esperimento. Al termine dell'esperimento, è possibile visualizzare le prove, ordinare in base ai parametri dell'obiettivo e fare clic con il pulsante destro del mouse per distribuire il modello per l'uso in altri ambienti.
Fase 5. Scopri le fasi dell'esperimento di SageMaker Autopilot
Mentre il tuo esperimento è in corso, puoi scoprire e analizzare le diverse fasi dell'esperimento SageMaker Autopilot.
Questa sezione fornisce ulteriori dettagli sulle fasi dell'esperimento SageMaker Autopilot:
- Analisi dei dati
- Elaborazione delle caratteristiche
- Ottimizzazione dei modelli
Nota: per ulteriori informazioni, consulta la pagina Output notebook Autopilot SageMaker.
Analisi dei dati
La fase Analisi di dati identifica il tipo di problema da risolvere (regressione lineare, classificazione binaria, classificazione multiclasse). Quindi, offre dieci pipeline candidate. Una pipeline combina una fase di pre-elaborazione dei dati (gestione dei valori mancanti, elaborazione di nuove caratteristiche, ecc.) con una fase di formazione del modello che utilizza un algoritmo ML che corrisponde al tipo di problema. Una volta conclusosi questo passaggio, il processo continua con la fase dell'elaborazione delle caratteristiche.
Elaborazione delle caratteristiche
Nella fase Elaborazione delle caratteristiche, l'esperimento crea set di dati di formazione e di convalida per ciascuna pipeline candidata, memorizzando tutti gli artefatti nel bucket S3. Durante questa fase, è possibile aprire e visualizzare due notebook generati automaticamente:
- Il notebook di analisi dei dati contiene informazioni e statistiche sul set di dati.
- Il notebook di generazione candidati contiene la definizione delle dieci pipeline. In realtà, questo è un notebook eseguibile: dunque è possibile riprodurre esattamente il processo di AutoPilot, capire come sono creati i diversi modelli e, se lo si desidera, continuare a modificarli.
Con questi due notebook, è possibile comprendere in dettaglio come i dati vengono pre-elaborati e in che modo si creano e si ottimizzano i modelli. La trasparenza è una caratteristica importante di Amazon SageMaker Autopilot.
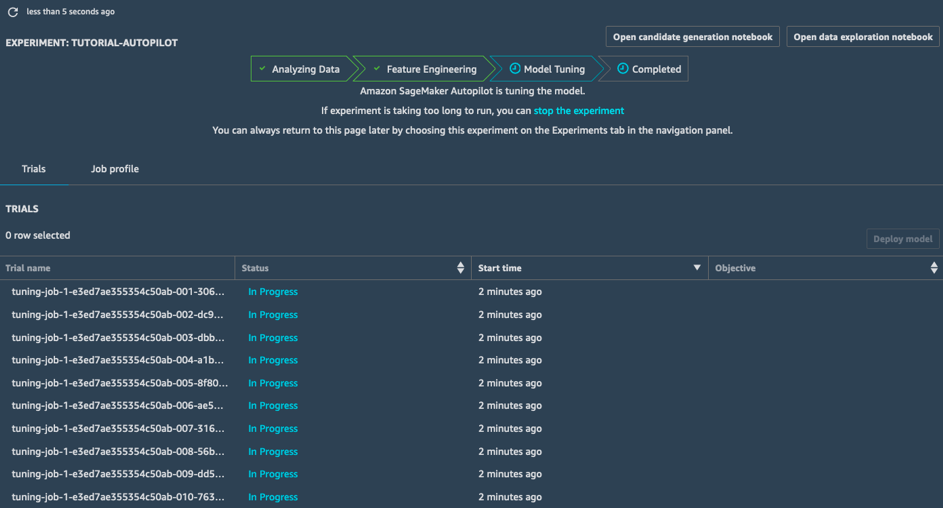
Ottimizzazione dei modelli
Durante la fase di Ottimizzazione dei modelli, per ciascuna pipeline candidata e il relativo set di dati pre-elaborato, SageMaker Autopilot avvia un processo di ottimizzazione dell'iperparametro; le attività di formazione associate esplorano un'ampia gamma di valori di iperparametro e convergono rapidamente in modelli ad alte prestazioni.
Una volta completata questa fase, il processo di SageMaker Autopilot è completo. Tutti i processi sono visibili e consultabili in SageMaker Studio.
Fase 6. Distribuisci il modello migliore
Una volta completato l'esperimento, puoi scegliere il miglior modello di ottimizzazione e distribuirlo su un endpoint gestito da Amazon SageMaker.
Segui queste fase per scegliere il miglior processo di ottimizzazione e distribuire il modello.
Nota: per ulteriori informazioni, consulta Scegli e distribuisci il modello migliore.
a. Nell'elenco Prove dell'esperimento, seleziona la carota accanto a Obiettivo per ordinare i processi di ottimizzazione in ordine decrescente. Il miglior processo di ottimizzazione viene evidenziato con una stella.
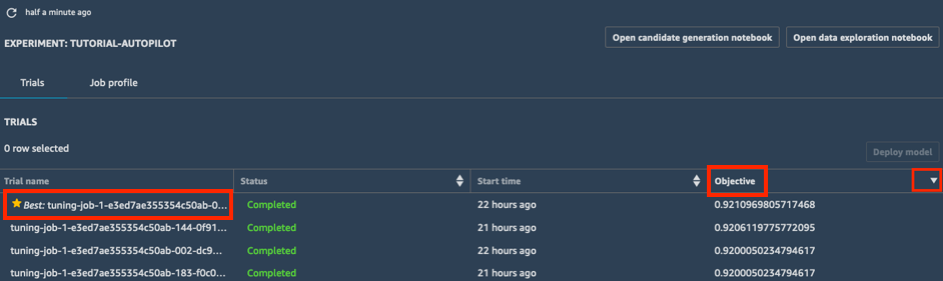
b. Seleziona il miglior processo di ottimizzazione (indicato da una stella) e scegli Distribuisci il modello.
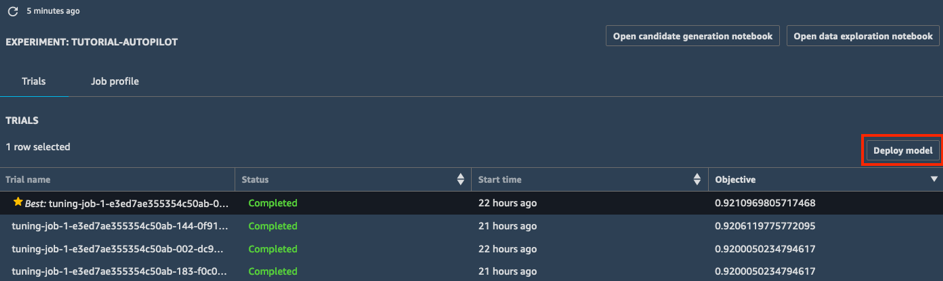
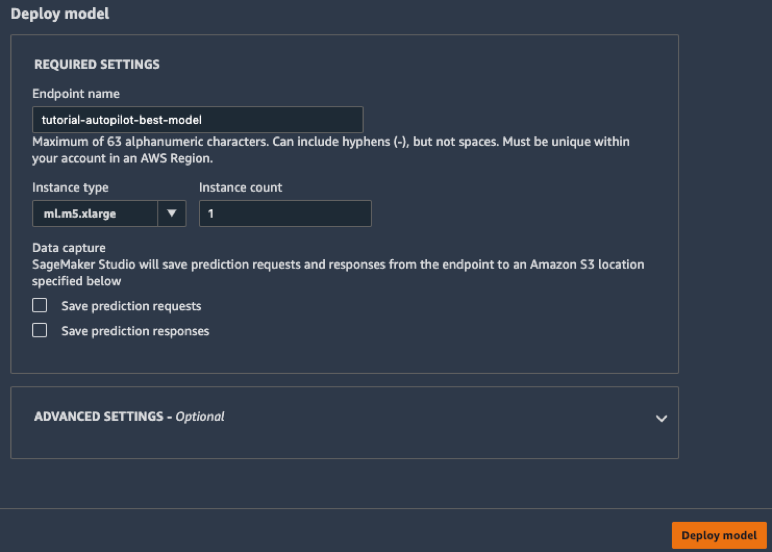
c. Nella finestra Distribuisci il modello, assegna un nome al tuo endpoint (ad esempio: tutorial-autopilot-best-model) e lascia tutte le impostazioni come predefinite. Scegli Distribuisci il modello.
Il modello viene distribuito su un endpoint HTTPS gestito da Amazon SageMaker.
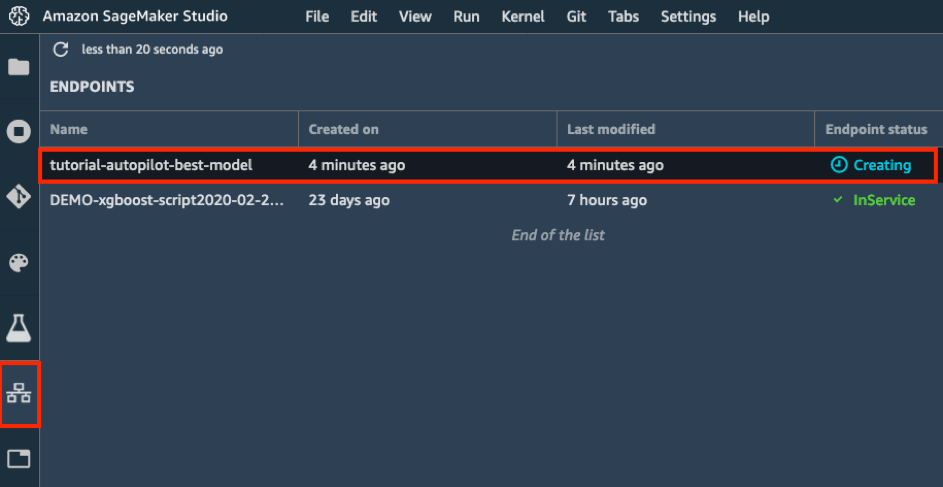
d. Nella barra degli strumenti a sinistra, seleziona l'icona Endpoint. La visualizzazione del tuo modello in fase di creazione richiederà alcuni minuti. Una volta che lo stato dell'endpoint è InService, è possibile inviare dati e ricevere previsioni.
Fase 7. Previsione del tuo modello
Ora che il modello è distribuito, è possibile prevedere i primi 2000 campioni del set di dati. A tale scopo, utilizza l'API invoke_endpoint nell'SDK boto3. Durante questo processo, elaborerà importanti parametri di machine learning come: accuratezza, precisione, riconoscimento e il punteggio F1.
Segui questi passaggi per iniziare a prevedere con il tuo modello.
Nota: per ulteriori informazioni, consulta Gestione del machine learning con esperimenti Amazon SageMaker.
Nel notebook Jupyter, copia e incolla il seguente codice e scegli Esegui.
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
Dovresti visualizzare l'output seguente.
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
Questo output è un indicatore di progresso che mostra il numero di campioni previsti.
Fase 8. Eliminazione
In questo passaggio, è necessario arrestare le risorse utilizzate in questo laboratorio.
Importante: l'arresto delle risorse che non vengono utilizzate attivamente consente di ridurre i costi e costituisce una best practice. La mancata interruzione delle risorse determineranno costi non desiderati.
Elimina il tuo endpoint: nel tuo notebook Jupyter, copia e incolla il seguente codice e seleziona Esegui.
sess.delete_endpoint(endpoint_name=ep_name)Se desideri eliminare tutti gli artefatti di formazione (modelli, set di dati pre-elaborati, ecc.), copia e incolla il codice seguente nella cella del codice e scegli Esegui.
Nota: assicurati di sostituire ACCOUNT_NUMBER con il numero del tuo account.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Congratulazioni
Hai creato un modello di machine learning con la massima precisione e in modo automatico con Amazon SageMaker Autopilot.
Fasi successive consigliate
Fai un tour di Amazon SageMaker Studio
Ulteriori informazioni su Amazon SageMaker Autopilot
Per ulteriori informazioni, leggi il post del blog o consulta la serie di video di Autopilot.